The encoding algorithm is to be illustrated using an example:
• Suppose the string $\boldsymbol{ABBCBCABABCAABCAAB}$ is to be compressed using the LZ78.
Steps:
• Initialy an emtpy dictionary is to be constructed with two columns, one for the dictionary entry and a the other of the its index.
• The first input in our example is "A" which is to be encoded. The algorithm checks if "A" already exist in the dictionary, if not, as in our case, "A" is inserted into the dictionary and an encoded codeword (output) of the format $\left(i,S\right)$ is to represent "A" in which $S$ is the string to be inserted into the dictionary, and $i$ is the dictionary index of the prefix of the input to be encoded. In our case with input "A" there is not prefix to it, therefore $i$ would be "0" and the output codeword would be $(0,A)$.
• For the second input "B", the same would happen as in the first input "A" and an output codeword of $(0,B)$ would be added to the output stream.
• For the third input "B", the algorithm will check its existence in the dictionary to find it at index 2.
• The algorithm would keep looking at the next input until a string is found which is NOT in the dictionary.
• In our case here, the string "BC" is not in the dictionary and thus would be added to it, and the output would be $(2,C)$, where 2 reffers to the location of the string $B$ in the dictionary
• The algorithm continues the same as before until all the inputs are encoded and a stream is displayed representing the compression/encoding of the input data as shown below:
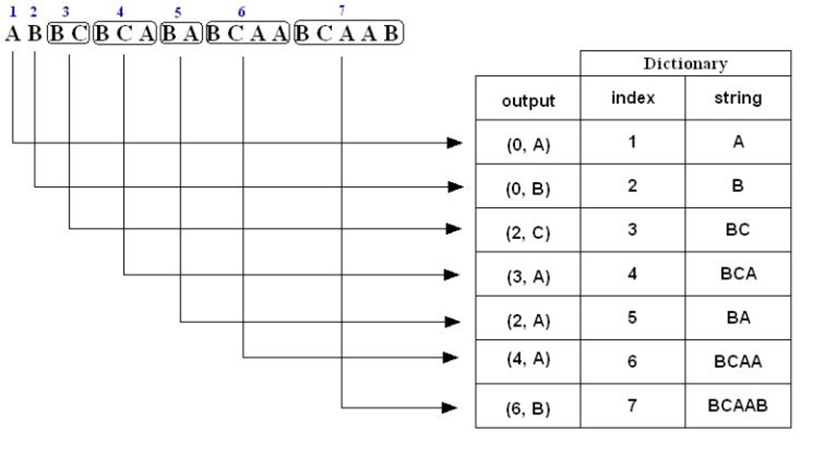
The encoded/compressed data:
$$\boldsymbol{(0,A)(0,B)(2,C)(3,A)(2,A)(4,A)(6,B)}$$